How Dropbox built an evaluation pipeline for AI search
With Josh Clemm, VP of Engineering
Dropbox keeps life organized for more than 700 million registered users across approximately 180 countries, with a mission to design a more enlightened way of working.
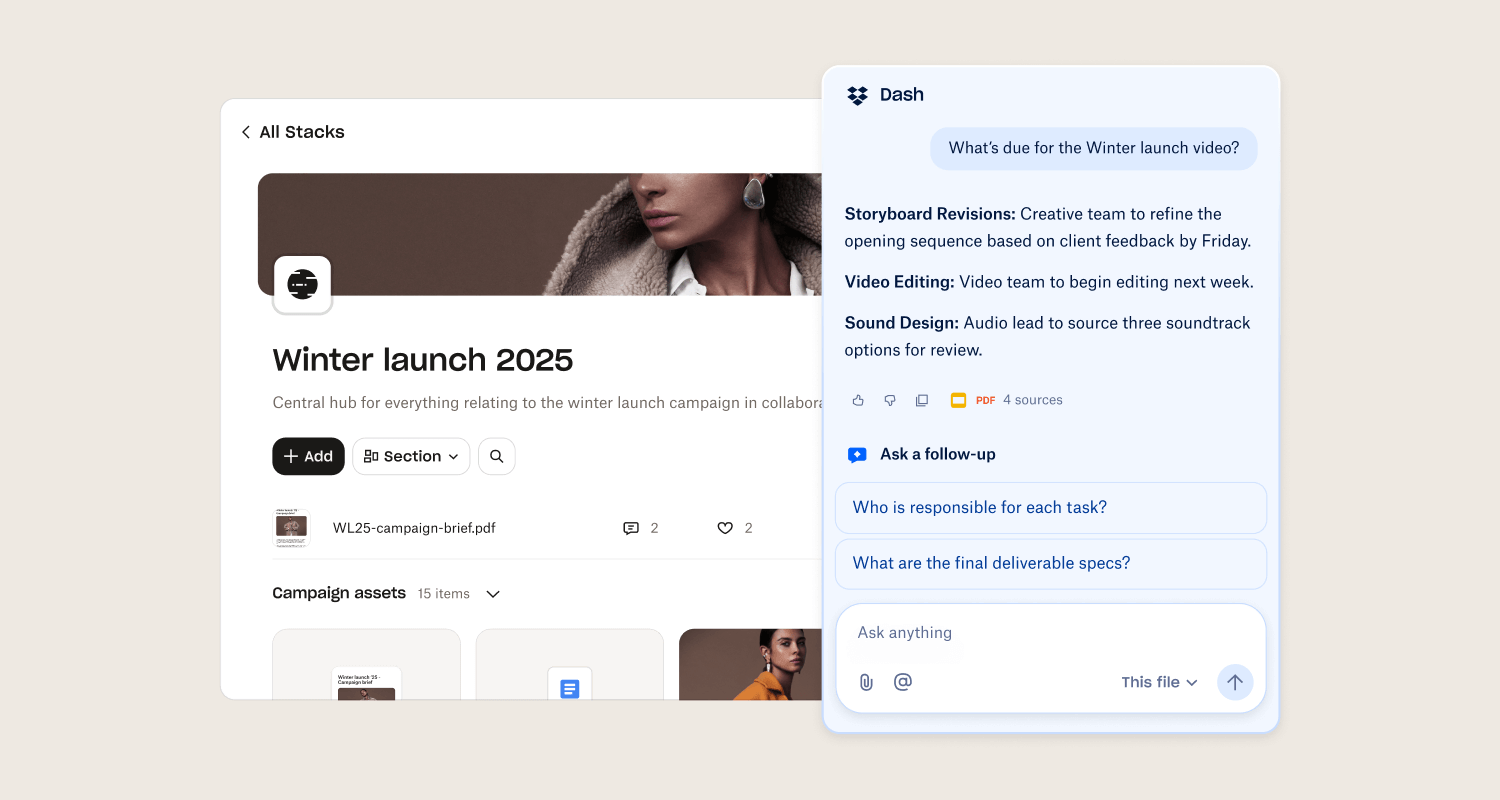
Recently, Dropbox launched Dash, which uses AI to connect files, messages, and projects in one workspace, so teams can search across tools, share with context, and keep work moving without juggling a dozen tabs.
Josh Clemm, VP of Engineering, leads the teams building Dash. With Braintrust, they've gone from spreadsheets and public datasets to a comprehensive, multi-tier evaluation system that runs over 10,000 tests and catches regressions in real time.
From public datasets to internal data
Like many teams, Dropbox started its eval journey with publicly available datasets: Google Natural Language Questions, MS MARCO, Microsoft Musique, and even the Enron email corpus. The team ran prompts and model combinations against these datasets to build a quick baseline.
We started how a lot of companies do. We looked at a lot of public data sets. It gave us a quick baseline, a quick gut check, but you plateau very quickly. And you have to start to think about more internally developed data sets. So we looked at a lot of representative samples, queries that a lot of Dropboxers are using day to day and trying to understand. These are more relevant content types to how people would be using our tool.
But they quickly realized the limitations of this approach, and sought out internal data to improve their evals. The team moved to representative samples of queries that Dropbox employees use day to day, which better reflected how people would actually interact with Dash. However, the process remained manual, relying on spreadsheets and ad-hoc coordination.
Hitting scaling limits
As more engineers began working on Dash and its AI functionality, the manual approach broke down. Multiple people modifying prompts simultaneously led to conflicts, and when new fixes were introduced, problems arose elsewhere.
Everybody wants to modify the prompt. A bug report came in so I'm gonna go add this additional change to the prompt, and of course it causes another issue to come up. It becomes a bit of a whack-a-mole situation.
Versioning prompts, running experiments in sandboxes, and gaining confidence that a fix would not regress other use cases required a more scalable platform. That's when Dropbox brought in Braintrust.

Before Braintrust
Couldn't scale
Building a multi-tier testing pipeline
In traditional software development, engineers run a suite of tests — unit tests, integration tests, and UI tests — to increase the confidence that changes won't break any other part of the system.
Though AI is different, it's still necessary to have the same comprehensive, multi-tier testing. AI products might generate hallucinations, or bad formatting, which can erode user trust. This is why the Dropbox team is so focused on ensuring the quality of its AI applications.
Evals are how Dropbox applies this testing rigor to its AI, and with Braintrust they've built a structured, multi-tier testing pipeline:

- Pre-merge smoke tests (150 tests). Before a PR can be merged, proposed changes run against 150 targeted tests to catch major regressions quickly.
- Full suite post-merge (10,000+ tests). After merge, the full evaluation suite runs across all scores to ensure no regressions across the system.
Being able to ship code with confidence is incredibly important. Evals are that for AI. You do not want to push something out and get unexpected results.
- Online LLM-as-a-judge in production. Sampled production queries run against the same rubric as offline tests, enabling real-time regression detection with dashboards and alerts.
Evolving from generic to specialized scoring
The team's evaluation metrics evolved alongside the product. Initial scores used traditional NLP metrics like ROUGE, BLEU, and cosine similarity. But these failed to capture what mattered for an enterprise AI product: citations, hallucination reduction, grounding in source material, and tone.
Over time as more and more usage comes in, you recognize that there's probably a much more narrow and specialized way of grading and scoring these responses.
This is why Dropbox adopted LLM-as-a-judge scoring. They started with broad rubrics covering correctness, formatting, and tone, then narrowed over time to specialized evaluations as usage patterns revealed what customers were actually trying to accomplish in Dash. With Braintrust, they could define these scores and version them as new data came in.
Turning production traces into a quality feedback loop
When someone gives a thumbs up or thumbs down on a response in Dash, that interaction becomes a valuable trace. The team can see what source objects were retrieved, what the prompt looked like, and how things were scored, making it easy to understand what went right or wrong. These traces feed back into new test sets, inform prompt modifications, and guide fine-tuning decisions.
It creates a little mini postmortem of what went wrong, and that can feed into either a new test set. Braintrust allows us to set up that flywheel.
This feedback loop is impossible with public datasets. The best AI products are built from production data that captures real usage, in real time. Josh's team now relies on Braintrust to both learn from and iterate on this real-world data.
Evals as the new PRD
The evals have become the new PRD. You need to really recognize what success looks like, what good looks like, how you want to apply your own judgment and think about taste.
Today, product development needs to account for the nature of AI products and how users interact with them. Teams need to understand their use cases and plan how to eval their products from the start. At Dropbox, evaluation criteria are defined before product development begins. Product teams codify what success looks like, how to apply judgment, and what quality means as part of the product specification process.
Key takeaways
- Start with public datasets, but graduate quickly. Public datasets provide a baseline, but real quality improvements come from internally developed datasets that reflect actual usage patterns.
- Build multi-tier testing. Fast smoke tests pre-merge, comprehensive test suites post-merge, and online judging in production ensure confidence.
- Move from generic to specialized scoring. As usage grows, narrow evaluation rubrics to match the specific jobs users are trying to accomplish.
- Set up the production flywheel early. Thumbs up/down feedback, trace analysis, and continuous dataset creation turn real-world usage into systematic quality improvement.
- Define evals before building features. Clarifying success criteria as part of the product spec process ensures alignment between what is built and what is measured.
Thank you to Josh Clemm for sharing Dropbox's story.
Build a multi-tier evaluation pipeline for AI
Learn how Braintrust helps teams like Dropbox move from spreadsheets to a comprehensive evaluation system with pre-merge smoke tests, full suite coverage, and online LLM-as-a-judge scoring in production.
Read more customer stories
How Notion evaluates AI at scale across 70 engineers
“Eval-driven development is the new test-driven development. Any projects that we take up, the first step is identifying the eval set.”
“Loop was our way of getting data or synthesizing log data more efficiently at an aggregate level. We use it to find common error patterns every single week.”